- Advertising
- Bare Metal
- Bare Metal Cloud
- Benchmarks
- Big Data Benchmarks
- Big Data Experts Interviews
- Big Data Technologies
- Big Data Use Cases
- Big Data Week
- Cloud
- Data Lake as a Service
- Databases
- Dedicated Servers
- Disaster Recovery
- Features
- Fun
- GoTech World
- Hadoop
- Healthcare
- Industry Standards
- Insurance
- Linux
- News
- NoSQL
- Online Retail
- People of Bigstep
- Performance for Big Data Apps
- Press
- Press Corner
- Security
- Tech Trends
- Tutorial
- What is Big Data
How to Choose the Right Programming Language for Your Big Data Initiatives (part 2)
In 2016 we have published an article on the right programming language for your Big Data Initiatives covering R, Scala, Python, and Java. Things move fast in big data, so it is high time for a follow-up. Let’s cover Julia, SAS, MATLAB, Go, and F#.

In 2016 we have published an article on the right programming language for your Big Data Initiatives covering R, Scala, Python, and Java. Things move fast in big data, so it is high time for a follow-up. Let’s cover Julia, SAS, MATLAB, Go, and F#.
C & C++ Are Still Game
In industries where fast execution speeds are a low-level requirement, languages which “sit” closer to the hardware, like C and C++, are still the norm. Especially in high-frequency finance, fast and nimble algorithms couldn’t exist without the high execution speeds of C++.
However, for most purposes, a data scientist will resort to using a more comfortable to use programming language, like Python, which became the most used programming language in 2017, surpassing Java & C++. Having covered R, Scala, Python & Java in 2016, let’s now look at F#, a name you have most likely run across.
F# (pronounced F Sharp)
The F# Software Foundation develops F#, and it follows Microsoft’s CLI open standard, the language being supported by Microsoft among others. It is a functional language at its core, which many coders may find difficult to understand at first, but their data analysis scripts using FsLab can be “compiled and deployed into cross-platform web and cloud-hosted production environments, including Jupyter notebooks and SAFE-Stack cloud services.”
F# is production ready offers a couple of advantages, as being very concise and convenient, has a powerful type system and supports asynchronous programming and paralleling.
F# offers “Markdown scripts and notebooks provide environments comfortable for scientists, data analysts, and developers, producing print-ready reports with embedded charts, code snippets and mathematics using HTML or PDF.”
Go
Go was created by Google and its one of the languages on the rise. It is statically typed, following the legacy of C. Just like F#, it is open-sourced. Similar to Python, Go code is concise and readable. Here is a table of its strengths versus the most common programming languages. Of course, this Pakt’s subjective evaluation.
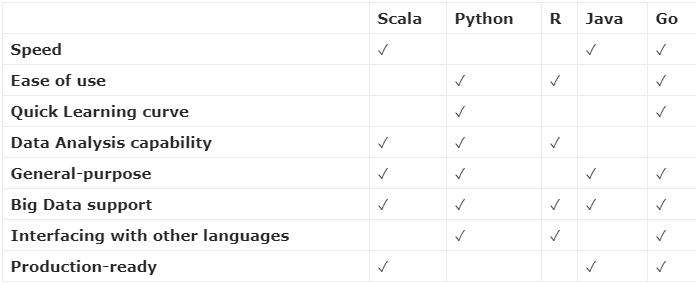
Many of the hottest modern infrastructure projects are powered by Go, including Kubernetes, Docker, Consul and many more. It is slowly turning into a go-to language for DevOps, web servers, and microservices. Given that is easy to learn, easy to deploy, fast, and has a great set of tools for developers you should consider it for your Big Data initiative.
MATLAB (matrix laboratory)
MATLAB is developed by MathWorks which also develops Simulink that is a graphical environment for modeling. The products go well together and support data analysis and simulation.
MATLAB 1.0 was released in 1984 and has over 3 million users, making it one of the oldest languages. It features a big community and resources, developed in time. Also many updates from 1.0 to the current version of 9.4 released in March 2018.
MATLAB is designed with engineers, scientists, and mathematicians in mind, aiming to express Mathematics naturally. This can make MATLAB inconvenient for people that do big data but are not proficient in Math. However, they are not MATLAB’s target user, as they clearly state on their website:
“Everything about MATLAB is explicitly designed for engineers and scientists:
- Function names and signatures are familiar and memorable, making them as easy to write as they are to read.
- New function interfaces undergo a rigorous design process that typically involves dozens to hundreds of developer-hours per function.
- The desktop environment is tuned for iterative engineering and scientific workflows.
- Integrated tools support simultaneous exploration of data and programs, letting you explore more ideas in less time.
- Documentation is written for engineers and scientists, not computer scientists.”
Julia
Julia is the newest language on our list. Our girl Julia was developed by three males and appeared six years ago for the first time. It is not as widely used, but some of the users have reported up to 10 times increase in speed in some model estimations, compared to MATLAB, which was previously used.
Like Go, Julia is on the rise because it is JIT-compiled, closely matching the speed of C, as presented in the intro paragraph, yet has a straightforward modern syntax. Julia does not have as many resources as other languages, yet Python or C libraries are easy to call in Julia.
One of the peculiar sides of Julia is its metaprogramming capabilities, as Julia programs can generate other Julia programs, which few languages like Lisp used to do.
Compared to Python, Julia is far faster, more math-friendly, but lacks Python’s colossal community and third-party packages, yet Julia is on the rise, so watch out for this.
SAS
SAS is the oldest language on our list and is a programming language mostly used for statistical analysis. It was released in 1976 by the SAS Institute after being developed for ten years at the North Carolina State University. SAS reached version 9.4 this year, while his sister SAS Viya 3.4. Viya is not a replacement, using Viya in conjunction with SAS, you can add cloud capabilities and other features to SAS, so they are used together.
One of the major pluses of SAS is big data analytics, and this is what they promote most. SAS moved to a big data programming language as a philosophy, working very well and highly integrated with Hadoop.
“High-performance analytics lets you do things you never thought about before because the data volumes were just way too big. For instance, you can get timely insights to make decisions about fleeting opportunities, get precise answers to hard-to-solve problems and uncover new growth opportunities – all while using IT resources more effectively.”
Source: SAS.
A Replacement for a Conclusion
Choosing a programming language many times boils down to the type of problem which you are trying to solve. It is also a question of whether your team has the necessary knowledge and experience to use that specific language. Unfortunately, usually there isn’t really one which could fulfill all your big data needs. The majority of big data infrastructures employ a whole stack of languages, each one being able to solve a specific task very efficiently.
The most important consideration to take when planning your big data architecture is to think carefully about what purpose it will serve. Will you be building large scale predictive algorithms, will speed play a crucial role and will you require real-time analytics or just batch processing?
Having answered the above questions, you will be able to boil down your choices to one or two specific languages. After that, it will be a matter of your team’s knowledge, experience and existing technology stack for which one to choose.
Readers also enjoyed:

Leave a Reply
Your email address will not be published.